
This approach involves using the same database and the same set of tables to host multiple client’s data. So any given table can include records from multiple tenants stored in any order, and a Tenant ID (Client ID) column associates every record with the appropriate Tenant/Client.
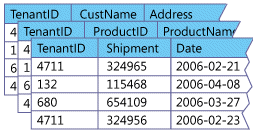
The figure above shows how this approach manages data in the DB Tables.
All Tenants/Clients will share the same set of tables, and a Tenant ID associates each tenant with the rows that it owns.
This shared schema approach has the lowest hardware and backup costs, because it allows you to serve a large number of tenants/clients using one database.
The shared-schema approach is appropriate when it is important that the application can be capable of serving a large number of tenants/clients with a small number of servers, which exponentially reduces the maintenance and support requirements of applications architected in this manner.
Extensibility Architecture for Shared Database/Shared Schema
We will now look at how such a Shared Database and Shared Schema approach does not limit the extensibility of the Application, to support changes to the Data Management requirements for each Client.
As designed, the ClaySys AppForms Tenant will include a standard database setup, with default tables, fields, queries, and relationships as per the overall design of the application. But different organizations will have their own unique needs that a rigid, inextensible default data model will not be able to address. For example, one customer of a job-tracking application system might have to store an externally generated classification code string with each record to fully integrate the system with their other processes. A different customer may have no need for a classification string field, but might require support for tracking a Category ID number, an integer. Therefore, we will have to develop and implement a method by which customers can extend the default data model to meet their needs, without affecting the data model that other customers use.
There are different options for achieving this requirement, and we will highlight them below. During the design phase of the ClaySys AppForms Project, we will finalize which option to go with.
Option 1 – Pre-allocated Fields
One way to make the ClaySys AppForms Tenant data model extensible is to simply create a present number of custom fields in every table you wish to allow tenants/clients to extend.
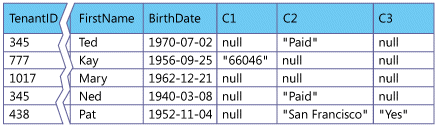
The figure above shows a table with a present collection of custom fields, labelled C1 through C3.
In the previous figure, records from different customers were intermingled in a single table, and a tenant ID field associates each record with an individual tenant. In addition to the standard set of fields, a number of custom fields can now be provided, and each customer can choose what to use these fields for and how data will be collected for them.
So now the question is how to handle data types? So for that we could simply choose a common data type for each custom field you create, but customers are likely to find this approach restrictive, as what if a customer has a need for three additional string fields and we’ve only provided one string field, one integer field, and one Boolean field. So we would provide this kind of flexibility by using the string data type for every custom field, and use metadata to track the real data type the tenant wishes to use as shown below.
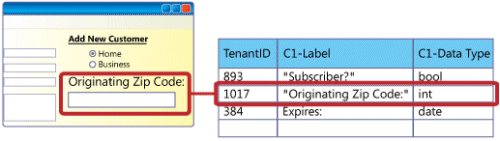
The figure above shows a custom field on a Web page, defined by an entry in a metadata table within the shared database.
In the example above, a tenant has used the application’s extensibility features to add a text box called Originating ZIP Code to a data entry screen, and mapped the text box to a custom field called C1. When creating the text box, the application would use validation logic to require that the text box contain an integer. As implemented, this custom field is defined by a record in a metadata table that includes the tenant’s unique ID number (1017), the label the tenant has chosen for the field (Originating ZIP Code), and the data type the tenant wants to use for the field (int).
You can track field definitions for all of the application’s custom fields in a single metadata table, or use a separate table for each custom field, for example, a C1 table would define custom field C1 for every tenant that uses it, and a C2 table would do the same for custom field C2, and so on.
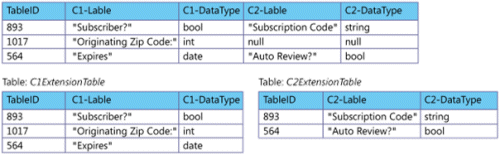
The figure above shows storing field definitions in a single metadata table, top, and in separate tables for each custom field.
The main advantage of using separate tables is that each field-specific table only contains rows for the tenants that use that field, which saves space in the database. (With the single-table approach, every tenant that uses at least one custom field gets a row in the combined table, with null fields representing available custom fields that the tenant has not used). The downside of using separate tables is that it increases the complexity of custom field operations, requiring you to use SQL JOIN statements to survey all of the custom field definitions for a single tenant.
When an end user types a quantity into the field and saves the record, the application casts the value for Originating ZIP Code to a string before creating or updating the record in the database. Whenever the application retrieves the record, it checks the metadata table for the data type to use and casts the value in the custom field back to its original type.
Option 2 – Name-Value Pairs for Data Extensibility
The Pre-allocated Fields option explained in the previous section is a simple way to provide a mechanism for tenants/clients to extend and customize the application’s data model.
Now we need to be aware of the limitations of this approach, even if they may not have an impact on client’s requirements. Certain limitations, like deciding how many custom fields to provide in a given table involves making some trade off. Too few custom fields, and tenants will feel restricted and limited by the application, too many, and the database becomes wasteful, with many unused fields. In certain cases, both can happen, with some tenants under-using the custom fields and others demanding even more.
We don’t expect the limitations above to be a factor for client, and if we find it to be a limitation for any scenario within the Core ClaySys AppForms Tenant, we will use the approach below.
The approach is to allow customers to extend the data model arbitrarily, storing custom data in a separate table and using metadata to define labels and data types for each tenant’s custom fields.
You can see from the figure below how an extension table allows each tenant/client to define an arbitrary number of custom fields.
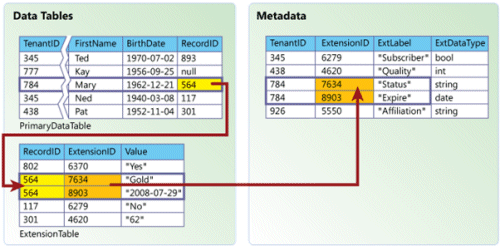
Here, a metadata table stores important information about every custom field defined by every tenant, including the field’s name (label) and data type. When an end user saves a record with a custom field, two things happen. First, the record itself is created or updated in the primary data table; values are saved for all of the predefined fields, but not the custom field. Instead, the application creates a unique identifier for the record and saves it in the Record ID field. Second, a new row is created in the extension table that contains the following pieces of information:
- The ID of the associated record in the primary data table.
- The extension ID associated with the correct custom field definition.
- The value of the custom field in the record that’s being saved, cast to a string.
This approach allows each tenant to create as many custom fields as necessary to meet its business needs. When the application retrieves a customer record, it performs a lookup in the extension table, selects all rows corresponding to the record ID, and returns a value for each custom field used. To associate these values with the correct custom fields and cast them to the correct data types, the application looks up the custom field information in metadata using the extension IDs associated with each value from the extension table.
This approach makes the data model subjectively extensible while retaining the cost benefits of using a shared database. The main disadvantage of this approach is that it adds a level of complexity for database functions, such as indexing, querying, and updating records. This is a good approach to take if you wish to use a shared database, but also anticipate that your customers will require a considerable degree of flexibility to extend the default data model.
For that we would recommend the Shared Database for the Core CLAYSYS APPFORMS TENANT, with the Pre-allocated Fields option as the primary data extensibility option, to meet custom requirements for clients.
For more complex Data Extensibility requirements, we would recommend the Data Model of the Core CLAYSYS APPFORMS TENANT SQL Database to be extended using additional tables as described above, only for scenarios where we feel the data model extensions could server most of ’s other clients on the Core CLAYSYS APPFORMS TENANT system. If the Data Model extensions are unique to only a particular client, then it would be most practical to simply use a separate SQL Database specific to that client for data extensibility, instead of adding additional tables in the Core CLAYSYS APPFORMS TENANT DB for a specific client. This separate SQL DB can also then be used for Custom Functionality being developed in ASP.Net for that specific Client.
Custom Columns
There is also an option to extend the Core CLAYSYS APPFORMS TENANT Data Model, for specific client requirements where custom columns can be added to Core CLAYSYS APPFORMS TENANT tables directly. The architecture with which this could be made to work is highlighted below, but we would not recommend it for client’s requirements, as it will make the Core ClaySys AppForms Tenant DB maintenance more complex.
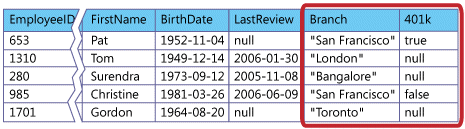
The figure above shows how custom rows can be added to a dedicated table without altering the data model for other clients/tenants in the Core ClaySys AppForms Tenant DB.
This architecture pattern is appropriate for separate-database or separate-schema applications, because each tenant has its own set of tables that can be modified independently of those belonging to any other clients. From a data model standpoint, this is the simplest of the three extensibility patterns, because it does not require you to track data extensions separately. On the application architecture side, though, this pattern is more difficult to implement, because it allows tenants to vary the number of columns in a table.
The Custom Columns option above is only to cover it for the purpose of addressing all possible architecture options for Data Extensibility using a Shared Database. But when we finalize an architecture for the client, we will consider using a variation on the Pre-allocated Fields or Name-Value Pairs pattern to reduce development effort and complexity, allowing client and vendors such as ClaySys to write application code that can assume a known and unchanging number of fields in each table.
Get Started with our Appforms Development Services